
What is Tokenization process in Informatica MDM?
There are two types of Match Strategy-Fuzzy and Exact.
The Tokenization process runs only on Base Objects with Fuzzy match strategy. Tokenization is the process of identifying the Match pairs between the records(Fuzzy Match Key) by generating and comparing tokens. Tokenization generates 1-20 tokens for each record of Fuzzy Match Key depending on the Key width and the length of the record. A token is an 8 char system generated value that are stored in BaseObject_STRP table(column-SSA_KEY).If there is a match between the tokens of two records,then they are identified as Match Pairs.The process of matching is only executed on these match pairs.So tokenization is basically the first step in Matching Process before executing the match process.Match tokens are generated in MDM Hub Console by executing the 'Generate Match Tokens' Batch Job in the Batch viewer after the staging and loading process are done.
1)Select Match/Merge Setup option inside the Base Object and set Match/Search Strategy in 'Properties' tab as Fuzzy.

2)Define the match path in 'Paths' tab as it allows to traverse the hierarchy between the records.This allows us to use the match columns from related table or the same table.

3)Add Match Columns and Fuzzy Match Key under the 'Match Columns' tab.There can be only one Fuzzy Match Key.We can define either Fuzzy and Exact Columns types for Fuzzy Match Strategy(In Exact,only Exact match columns can be defined)

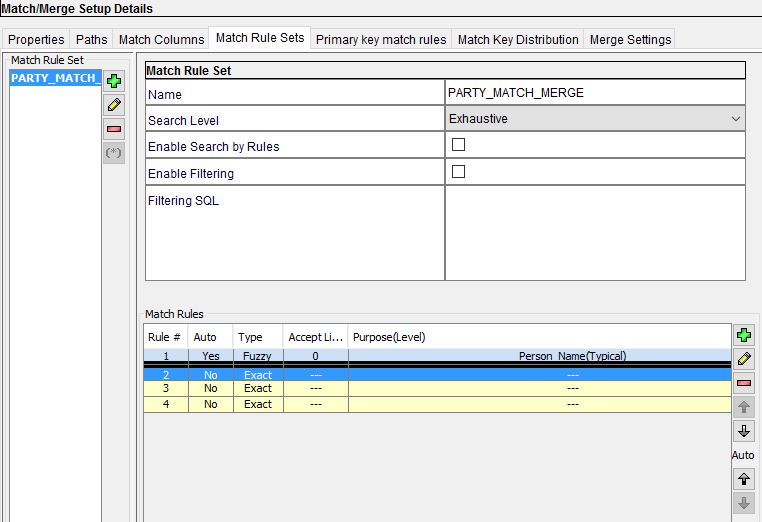
4)Add match rule sets in 'Match Rule Sets' tab. Set the required search level and Merge type(Auto or Manual)by using the icons at the right end, and save the changes.

5)Run the 'Generate Match Tokens' Batch Job in Batch Viewer.

The Tokenization process runs only on Base Objects with Fuzzy match strategy. Tokenization is the process of identifying the Match pairs between the records(Fuzzy Match Key) by generating and comparing tokens. Tokenization generates 1-20 tokens for each record of Fuzzy Match Key depending on the Key width and the length of the record. A token is an 8 char system generated value that are stored in BaseObject_STRP table(column-SSA_KEY).If there is a match between the tokens of two records,then they are identified as Match Pairs.The process of matching is only executed on these match pairs.So tokenization is basically the first step in Matching Process before executing the match process.Match tokens are generated in MDM Hub Console by executing the 'Generate Match Tokens' Batch Job in the Batch viewer after the staging and loading process are done.
1)Select Match/Merge Setup option inside the Base Object and set Match/Search Strategy in 'Properties' tab as Fuzzy.

2)Define the match path in 'Paths' tab as it allows to traverse the hierarchy between the records.This allows us to use the match columns from related table or the same table.
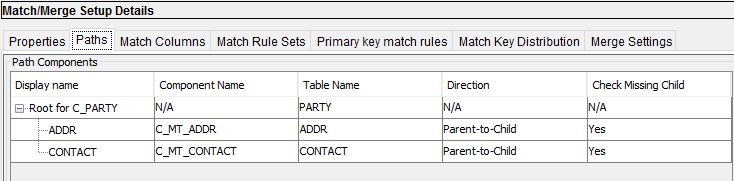
3)Add Match Columns and Fuzzy Match Key under the 'Match Columns' tab.There can be only one Fuzzy Match Key.We can define either Fuzzy and Exact Columns types for Fuzzy Match Strategy(In Exact,only Exact match columns can be defined)

4)Add match rule sets in 'Match Rule Sets' tab. Set the required search level and Merge type(Auto or Manual)by using the icons at the right end, and save the changes.
5)Run the 'Generate Match Tokens' Batch Job in Batch Viewer.


![SIP-20881: ERROR: The batch job did not start because a batch job is already running on table [Table Name] Informatica MDM](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjykThFEubAZcw1tT3uo_clDXku01inq73UN5iz_GPuyqqkKzGgJQMIw_JfwJHCdOYWWXrxnaJfJpuBYDsoEJI6IdqnguruNXIfLpfPrsfruNYMwnfj0sNbWslx8EMJ9NCEiz2I4PeNHB0/s72-c/Capture.JPG)



Nice blog its very informative and useful blog keep sharing.
ReplyDeletePlanning to learn Informatica MDM Training
Informatica MDM Online Training
I appreciate you sharing this article. Really thank you. Informatica online training
ReplyDeleteHi Varsha,
ReplyDeleteThat’s really cool…. I followed these instructions and it was like boom… it worked well..
Does anyone know of a guide for the HL7 Parser using Informatica PowerCenter 10.1.1 and Informatica Developer 10.1.1 HotFix1?
I imported the HL7 Parser and have manually used the transformation to convert/view the XML output; However, I am struggling on figuring out how to add an unformulated source text file, an XML target, and importing it into PowerCenter so I can automate it.
Excellent tutorials - very easy to understand with all the details. I hope you will continue to provide more such tutorials.
Many Thanks,
Mahesh
Mastech InfoTrellis - Data and Analytics Consulting Company extending premier services in Master Data Management, Big Data and Data Integration.
ReplyDeleteVisit for More : www.infotrellis.com
Mastech InfoTrellis - Data and Analytics Consulting Company extending premier services in Master Data Management, Big Data and Data Integration.
ReplyDeleteVisit for More : https://mastechinfotrellis.com/data-management/
I think there is a need to look for some more information about Informatica and its crucial aspects.
ReplyDeleteInformatica Read Rest API
Nice post.
ReplyDeleteInformatica message Queue online training
Informatica message Queue training
Informatica power center online training
Informatica power center training
Manual Testing online training
Manual Testing training
Microservices online training
Microservices training
I cannot thank you enough for the blog.Thanks Again. Keep writing.
ReplyDeleteoracle sql plsql training
go langaunage training
azure training
java training
salesforce training
hadoop training
mulesoft training
linux training
mulesoft training
web methods training
Nice Post! Thank you so much for sharing great post with us.
ReplyDeleteUFUND